Confidential AI From GPU Enclaves
Hardware roots of trust
To trust a computer, we must know exactly what code it is running, and on exactly what hardware. We will derive all later claims of trustworthiness from these two facts, hence the name “roots of trust”. We rely on two hardware-based technologies to establish these roots: AMD SEV-SNP, present on Zen 3 or later CPUs; and the NVIDIA’s “Confidential Computing” mode, currently exclusive to the H100 GPU.
AMD SEV-SNP
SEV-SNP (“Secure Encrypted Virtualization” and “Secure Nested Paging”) is a CPU feature from AMD that lets CPUs launch isolated and encrypted virtual machines that do not trust the hypervisor. These are called confidential VM’s.
We use SEV-SNP to to prove to clients that they are connecting to a confidential VM in an isolated, secure context, running exactly the code specified by some hash. Here’s how we do that:
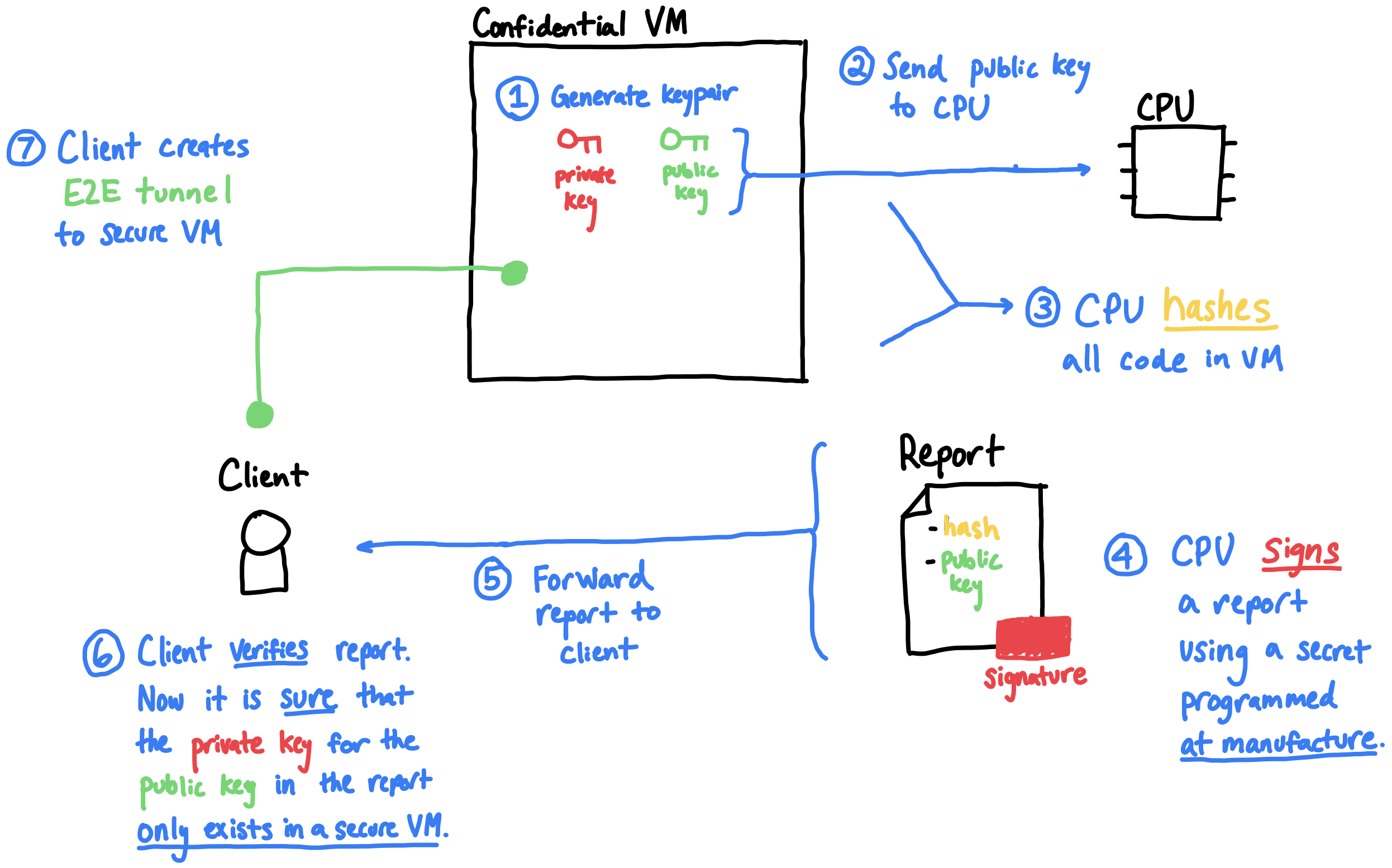
- An untrusted server launches a confidential VM using SEV-SNP. The VM boots, and generates a fresh public/private key pair.
- The VM sends the VM public key in a special request, available only inside a confidential VM, directly to the CPU.
- The CPU hashes (aka ‘measures’) all code running in the VM, producing a code hash.
- The CPU signs, using a chip secret key programmed by AMD at manufacture, an attestation report, which is a statement including:
- The code hash.
- The VM public key that was included in the request.
- The signed attestation is sent to a remote client.
- The remote client verifies that:
- The attestation is signed by a public key that AMD has marked as a genuine AMD CPU public key.
- The code hash is the expected value.
- If all checks pass, the client can safely encrypt data to the VM public key, knowing that it can only be decrypted inside the VM. So, the client connects to the VM using this public key over TLS, establishing a secure tunnel to the VM.
Security assumptions
The attestation process is convincing because we assume that:
- SEV-SNP encrypts the memory of guest VM’s using an ephemeral key residing in the CPU, so a malicious hypervisor cannot inspect or modify guest VM memory.
- The CPU measures all code running in the VM.
- Even with extended physical access, it is difficult to extract the chip secret key (the one used to sign attestations).
- AMD did not, at manufacture, make a copy of the chip secret key or a method for extracting it, and then later leak this to an adversary.
- AMD did not mark as genuine a chip public key that was not, in fact, embedded into an AMD CPU.
(1-3) are part of the underlying SEV-SNP technology; the main risk is that a bug in design or implementation by AMD breaks one of these assumptions. These are the most likely assumptions to be broken in practice.
For (4), we assume that AMD is not malicious at manufacture time of the given CPU. This is crucially not assuming that AMD behaves honestly going forward, and could be compared to trusting that the CPU, at manufacture, was programmed to do what you expect (one of the classic assumptions we must make to trust our computers at all).
(5) is a more online assumption - AMD maintains certificate chains up to a root key they control, and certifies that various chip public keys belong to genuine AMD chips. If the AMD root key, or some intermediate key, was compromised, an adversary could fake attestations, and then read secret client data1.
A simple mitigation, borrowed from TLS, makes this kind of attack easy to catch: we can pin the certificate chain that AMD provides for the chip when we purchase it. Now, if AMD later produces an attestation for a fake chip public key, there would be incontrovertible evidence of misbehavior - we would see two attestations for the same chip with different chip public keys. Using a collaborative, open transparency log, like we currently do for TLS certificates with Certificate Transparency, we could make such attacks almost certain to be caught.
The pinning and transparency log technique corners a malicious adversary: to mount an attack without getting caught, they must backdoor the AMD manufacturing process or CPU design for every chip of interest. This is a very high bar!
NVIDIA H100 Confidential Compute
The NVIDIA H100 GPU’s “Confidential Compute” (CC) mode makes the GPU safe to use from inside confidential VM’s. The confidential compute mode on the H100 is more limited than its CPU equivalent; it is must be used in conjunction with a confidential VM technology like SEV-SNP, rather than standalone.
In CC mode:
- Data transfers between the CPU and GPU over PCIe are encrypted by the host and decrypted only inside the GPU.2
- A single instance of the driver gets exclusive access to the GPU.
- Performance counters and JTAG access are disabled.
- Exiting CC mode requires resetting the GPU, erasing the contents of its memory.
- The GPU can produce a signed attestation containing:
- measurements of its VBIOS (the GPU firmware)
- the device model and identifier
The VM running in SEV-SNP connects to the GPU using PCIe passthrough, verifies that it is in CC mode, and then requests and checks the attestation. From then on, the GPU is in a known state, and the VM can use CUDA normally. The only performance degradation is for PCIe transfers, which are slower due to the encryption.
Security assumptions
The security assumptions for CC mode are similar to the SEV-SNP ones:
-
Even with physical access, it is difficult to directly read GPU memory.
- Extracting GPU memory much more difficult than on the CPU, since memory for these GPUs is on-die.
-
NVIDIA did not, at manufacture, make a copy of the GPU’s secret key or a method for extracting it, and then later leak this to an adversary.
-
A malicious VBIOS, even if signed by NVIDIA, would get caught by a similar pinning process as outlined previously.
From trusted boot to a trusted application
The code that SEV-SNP needs to measure (that is, cryptographically hash) is sometimes called the ’trusted code base’, or TCB. Essentially, the TCB is the set of code that a client needs to trust to assume that the behavior of an enclave is not malicious. To maintain confidentiality of user data, it is crucial that the attestation from an enclave includes a measurement of the entire TCB. For example, if we were running a confidential VM, and the attestation included a measurement of the application running in a VM, but not any of the OS, that would bad - the VM’s OS could behave arbitrarily maliciously (exfiltrate sensitive user data, etc) without the client having any way of knowing.
Ideally, the underlying enclave technology we are using would offer this natively; somehow, it would hash all code that could impact the behavior of the enclave, and then include this hash in the attestation.
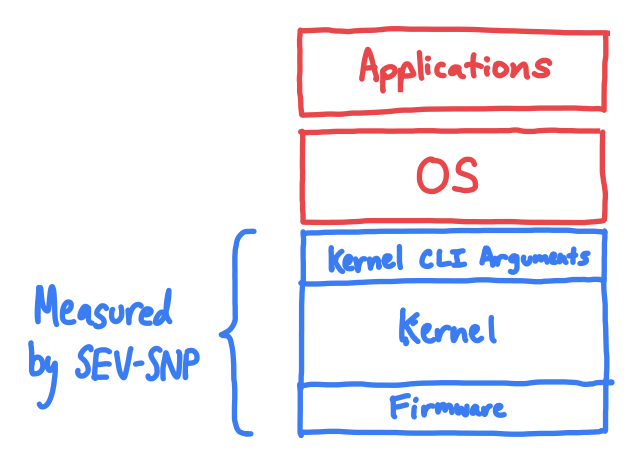
SEV-SNP only measures the kernel, initrd, firmware, and kernel CLI.
Unfortunately, SEV-SNP does not hash the entire VM when producing an attestation; in fact, it doesn’t even hash the application or OS. Instead, the only things hashed by SEV-SNP are the kernel, the kernel command-line parameters, and the initrd (also known as the ‘initramfs’, it is the initial filesystem and code loaded into memory that prepares for boot)3.
To make this hash actually include the OS and application code (for example, the Python code to run the machine learning model, the libraries it depends on, the NVIDIA driver, etc), we need to somehow bind the filesystem to one of the things that is actually hashed.
SEV-SNP is relatively new, and is still mostly run by public clouds (AWS, Google Cloud, Azure) that have their own proprietary solutions. They each instantiate a kind of “virtual TPM” to measure boot and then sign attestations. These systems contain opaque code and tend to require some ongoing trust in the cloud provider - they are aimed at enterprises concerned with regulatory compliance and protection from accidental leakage, rather than end users who need publicly verifiable confidentiality relying solely on the hardware root of trust.
Because of this, there is not yet a widespread standard for measuring the contents of a confidential VM and performing reproducible builds, though a large community of researchers are working on it through the Confidential Containers project. It will take a virtuous cycle of adoption and improvement to get robust standards.
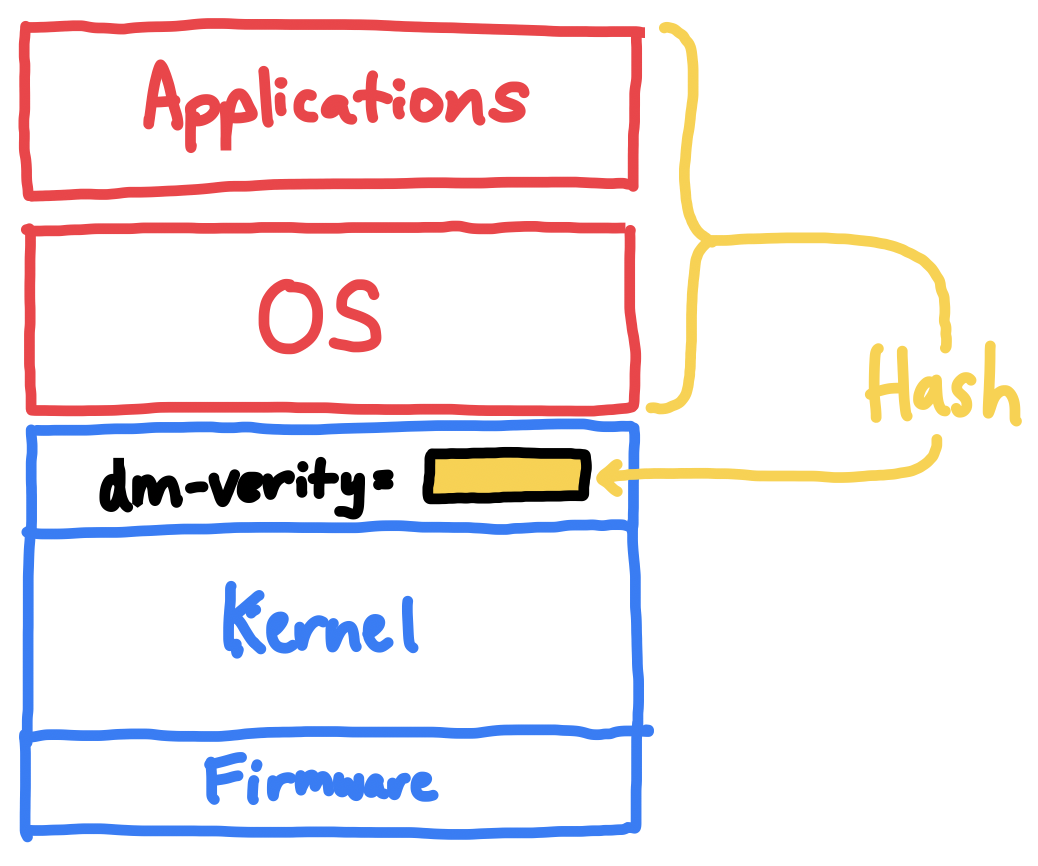
We embed a hash of the disk in the kernel CLI,
forcing it to be part of the overall SEV-SNP measurement.
As a first start, we use a kernel feature called dm-verity to measure the OS and application code. Originally designed for Chromebooks, and later used on Android, it hashes an entire block device and compares it to a root hash passed in from a separate device. We pass this root hash in as a kernel command-line parameter, which binds the disk’s root hash to the AMD SEV-SNP measurement, since it includes the kernel command-line parameters.
Public verifiability
We ultimately want someone to be able to reproduce our code measurement, so that clients can be sure what code is running in the VM. We see three possible levels of reproducibility:
- The service provider could publish the application code, build steps, and the final disk image used in production. Repeating the build locally may not produce an identical disk image due to non-determinism in the build, but the disk image used in production can be mounted and inspected by anyone.
- The service provider could publish the code, and then perform a build using a third-party CI system like GitHub Actions or GitLab CI/CD. The idea is that the build is performed by a more trustworthy third party, rather than the service provider itself. The output disk image is also still inspectable.
- The build is completely reproducible. The service provider can perform ‘public’ builds on several public CI/CD platforms, show that the hashes match, and even let users perform a local build that yields a matching hash.
We would like every enclave application to get to (3), but reproducible builds for a whole VM (including the OS) are really tricky, so we think (1) and (2) are pretty acceptable, depending on how complex the application is. As of 2023, the Blyss service just provides (1), but we are working towards (2).
Connecting attestation to TLS
We can use these building blocks to build a completely confidential LLM server! No entity - not even Blyss - can observe the interactions users have with the model.
It starts with Blyss building a VM containing the model and associated code for running it, publishing the build steps, final disk image and hash, and expected SEV-SNP measurement. This is ideally reproducible (see above) and public.
At boot, the VM follows the standard SEV-SNP process, and in addition verifies the disk image using dm-verity and verifies the GPU attestation. Ultimately, the VM combines all attestation data (the CPU report, the GPU report, and its public key) into a JSON file, and serves it at a fixed URL like /.well-known/attestation/complete-attestation.json.
Now, the VM requests a TLS certificate from Let’s Encrypt for the VM public key on some domain (example.com).
The exciting thing is that now, any external observer can cross reference Certificate Transparency logs, the public disk image, and the well-known attestation URL, and verify that the public key was generated properly inside the VM running the expected code! When end-users connect to example.com, they can be sure that they are connecting to an enclave! Any misbehavior will be visible in the Certificate Transparency logs, and an auditor could alert end users (more on this below).
Side channels
There are a myriad of side-channels that a malicious host can use to attempt to extract sensitive client data: caches, timing, power, disk and memory access patterns, and fault injections are the most significant.
There is extensive prior work on designing applications that minimize side-channel leakage on the CPU, especially inside enclaves. By following these best practices, its possible to greatly minimize these leaks.
On the GPU, especially for machine learning, there is less hardening experience. The high-level issue is that discrete GPUs4 are designed for peak performance, and until recently, it made little sense to try minimizing side channel leakage from them. Some leakage is inherent to the application - for text generation, a streaming API will inherently leak the timing pattern of generated tokens. We believe this level of leakage is acceptable, since it is already visible to passive network observers.
Auditing
To catch misbehavior, the system we outlined relies on public auditors who will read Certificate Transparency logs and cross-reference them with claimed code hashes and attestations. Thanks to the existing Certificate Transparency infrastructure, it is already extremely difficult to tamper with these logs. Clients that want the highest level of trust can perform these checks themselves when connecting the service (this is particularly easy from a backend service, running something like LangChain, or a desktop app, like Cursor).
We are committed to building technical infrastructure that makes it easy for anyone to perform an audit, and in the longer run, the organizational infrastructure to encourage CAs and other entities to perform these audits themselves. The attested web is young, but the eventual goal is “second green lock” - an indication in browsers of a correct attestation for the TLS connection active, and a link to the code running in the enclave.
Enclaves: a checkered past
Enclaves have a checkered past - and present. On the one hand, they have enabled huge leaps forward in real-world privacy for most people, through the now-widespread full-disk encryption on phones and computers. Apple in particular has pioneered using their Secure Enclave as a root, user-controlled secret to safeguard user data and provide end-to-encryption with secure and convenient recovery.
On the other hand, enclaves have often been used to make devices work against their own users. The origins of many enclave technologies lie in DRM enforcement (CPUs without SGX won’t play Blu-rays), and even today, controversial proposals like Web Environment Integrity aim to encourage more ’locking down’ of end-user devices, making it harder for users to install unauthorized software and maintain autonomy over their device.
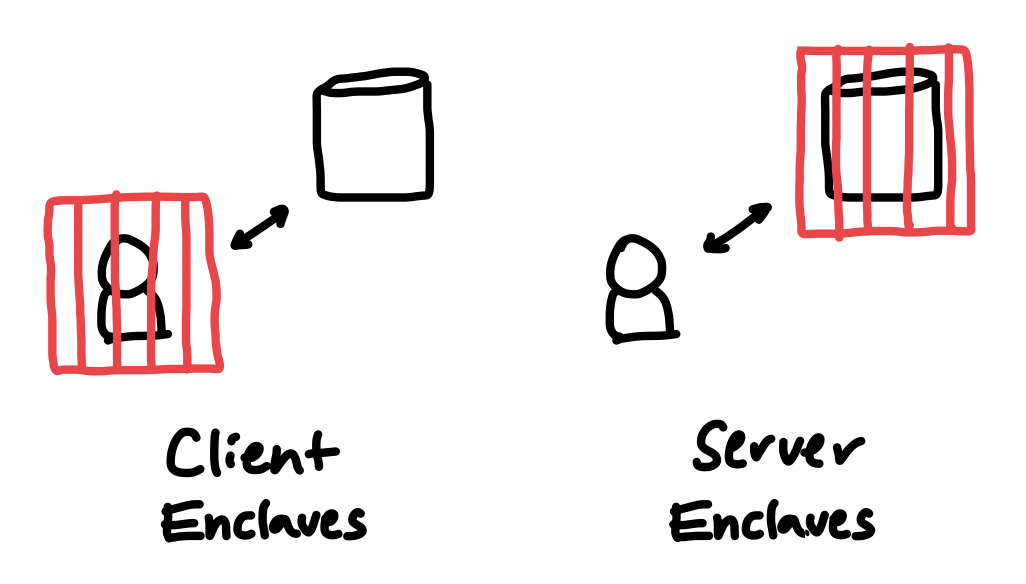
Client enclaves constrain the user, while server enclaves constrain the service.
There is a critical distinction between the use of enclaves on servers versus clients.
On clients, enclaves should behave as “user agents” - they should act on behalf of and with the consent of the user. Enclaves should be used to safeguard secrets, and prevent unauthorized access to the user’s data; they should not enforce limits on an authenticated user’s behavior.
On servers, instead of limiting what users can do, enclaves can impose limits on what services can do. Today, when users send data to a service, everything about how their data is processed and managed is subject to flimsy and ever-changing promises. Server enclaves let us flip that dynamic; now, users can force servers to commit upfront to what they do with user data, and the promise is actually binding!
We can actually use enclaves to improve, rather than chip away at, user privacy and autonomy.
Attacks
Enclaves of all shapes and sizes have been the subject of a constant stream of side-channel and microarchitectural attacks. Sometimes, they seem most useful for minting PhD theses.
Deploying secure and trustworthy enclaves on servers is not intractable. Just as it took many years and iterations to get TLS right, it will take time to build robust and secure enclave-based systems. We’re still getting better at mitigating microarchitectural attacks, and we are at least more aware of how hardware design and OS security intersect now that we’ve all been through Spectre, Meltdown, SGAxe, etc.

Enclaves aren’t perfect, but they are way better than the status quo
The fact that these systems are not perfect does not make the status quo acceptable. Today, there is nothing - you get no guarantees whatsoever when you send data to a machine learning service, or logging platform, or cloud provider. Moving from this status quo to enclaves is not a 100% solution; we will contend with supply chain and side channel attacks, and individual enclave technologies will continue to get broken and upgraded. But using enclaves represents a radical improvement over what we do today, and if widely deployed, would bring meaningful privacy to almost everyone.
Conclusion
The dream is services that don’t do just whatever they want, but instead make upfront, binding commitments to how they intend to use your data. The Blyss confidential LLM service is the first step towards that dream. If you want to use LLMs, but can’t just trust a third party with your most sensitive data, you should contact us.
-
Most users and businesses are not concerned that AMD will conspire against them, but negligence or a malicious third party are more realistic. ↩︎
-
Function-level resets (FLR), which only let you reset the GPU (wiping its memory), are unencrypted, and can be initiated by the hypervisor. ↩︎
-
In fact, even getting the attestation to include initrd and the kernel command-line parameters is not straightforward; it requires using custome kernels maintained by AMD, and is not yet included in the documentation from NVIDIA. ↩︎
-
On-die GPUs, like the ones in phones, actually do have some protections, since they sometimes perform security-sensitive tasks, like face or fingerprint matching. ↩︎